Usage
Installation
First make Pandas Check available in your environment.
# With uv
uv add pandas-checks
# Or with pip
pip install pandas-checks
Then import it in your code. It works in Jupyter notebooks, IPython, and Python scripts run from the command line.
import pandas_checks
After importing, you don't need to access the pandas_checks module directly.
💡 Tip:
You can import Pandas Checks either before or after your code imports Pandas. Just somewhere. 😁
Basic usage
Pandas Checks adds .check methods to Pandas DataFrames and Series.
Say you have a nice function.
def clean_iris_data(iris: pd.DataFrame) -> pd.DataFrame:
"""Preprocess data about pretty flowers.
Args:
iris: The raw iris dataset.
Returns:
The cleaned iris dataset.
"""
return (
iris
.dropna()
.rename(columns={"FLOWER_SPECIES": "species"})
.query("species=='setosa'")
)
But what if you want to make the chain more robust? Or see what's happening to the data as it flows down the pipeline? Or understand why your new iris CSV suddenly makes the cleaned data look weird?
You can add some .check steps.
(
iris
.dropna()
.rename(columns={"FLOWER_SPECIES": "species"})
# Validate assumptions
.check.assert_positive(subset=["petal_length", "sepal_length"])
# Plot the distribution of a column after cleaning
.check.hist('petal_length')
.query("species=='setosa'")
# Display the first few rows after cleaning
.check.head(3)
)
The .check methods will display the following results:
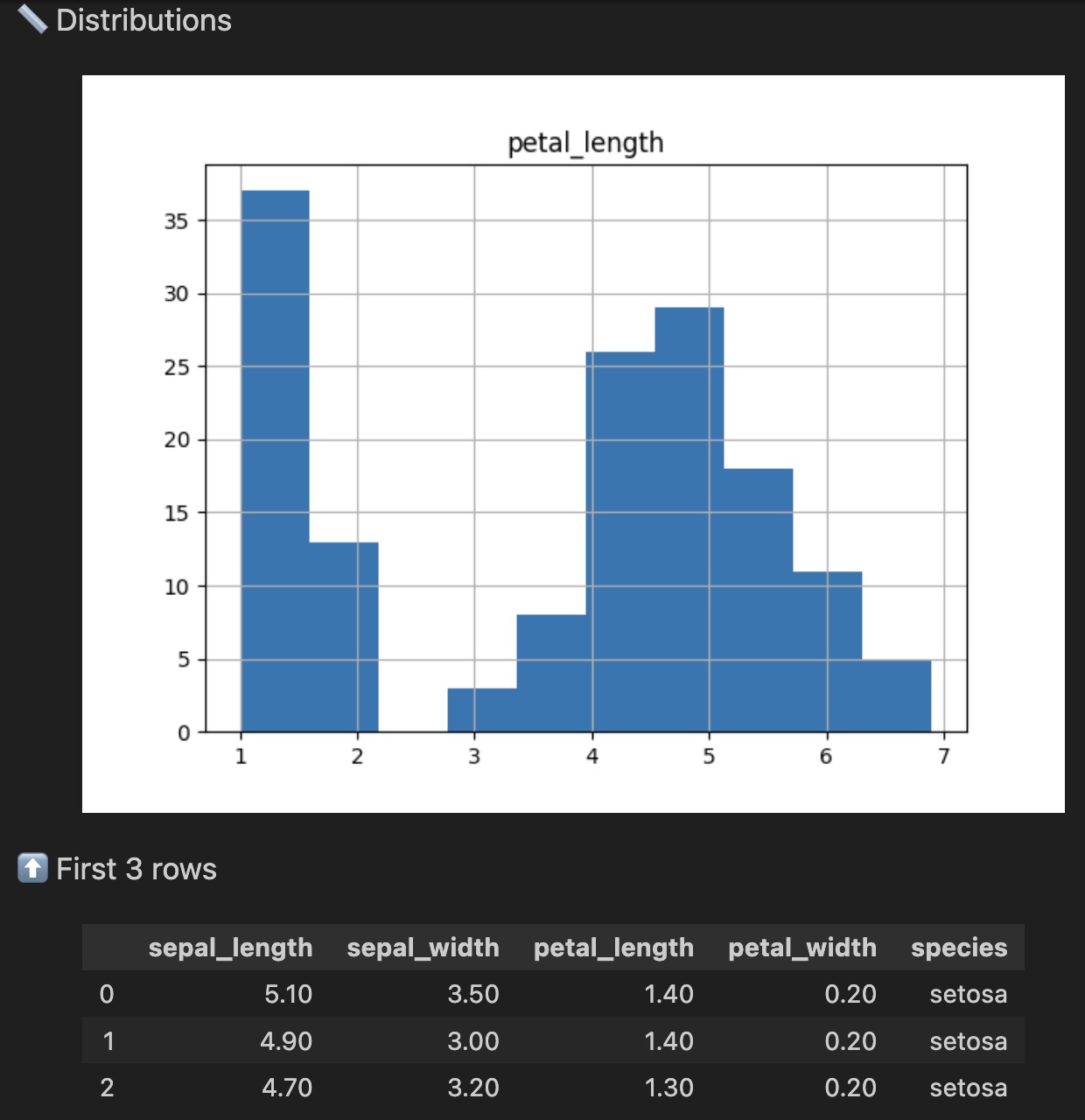
The .check methods didn't modify how the iris data is processed by your code. They just let you check the data as it flows down the pipeline. That's the difference between Pandas .head() and Pandas Checks .check.head().
Methods available
Here's what's in the doctor's bag.
Describe data
Standard Pandas methods:
.check.columns()- DataFrame.check.dtype()- Series.check.dtypes()- DataFrame.check.describe()- DataFrame | Series.check.head()- DataFrame | Series.check.info()- DataFrame | Series.check.memory_usage()- DataFrame | Series.check.nunique()- DataFrame | Series.check.shape()- DataFrame | Series.check.tail()- DataFrame | Series.check.unique()- DataFrame | Series.check.value_counts()- DataFrame | Series
New methods in Pandas Checks:
.check.function()- Apply an arbitrary lambda function to your data and see the result - DataFrame | Series.check.ncols()- Count columns - DataFrame | Series.check.ndups()- Count rows with duplicate values - DataFrame | Series.check.nnulls()- Count rows with null values - DataFrame | Series.check.nrows()- Count rows - DataFrame | Series.check.print()- Print a string, a variable, or the current dataframe - DataFrame | Series
Export interim files
Time your code
.check.print_time_elapsed(start_time)- Print the execution time since you calledstart_time = pdc.start_timer()- DataFrame | Series💡 Tip: You can also use this stopwatch outside a method chain, anywhere in your Python code:
from pandas_checks import print_elapsed_time, start_timer
start_time = start_timer()
...
print_elapsed_time(start_time)
Turn Pandas Check on or off
These methods can be used to disable subsequent Pandas Checks methods, either temporarily for a single method chain or permanently such as in a production environment.
.check.disable_checks()- Don't run checks. By default, still runs assertions. - DataFrame | Series.check.enable_checks()- Run checks again. - DataFrame | Series
Validate data
Custom:
Types:
.check.assert_datetime()- DataFrame | Series.check.assert_float()- DataFrame | Series.check.assert_int()- DataFrame | Series.check.assert_str()- DataFrame | Series.check.assert_timedelta()- DataFrame | Series.check.assert_type()- DataFrame | Series
Values:
.check.assert_all_nulls()- DataFrame | Series.check.assert_less_than()- DataFrame | Series.check.assert_greater_than()- DataFrame | Series.check.assert_negative()- DataFrame | Series.check.assert_no_nulls()- DataFrame | Series.check.assert_nrows()- DataFrame | Series.check.assert_positive()- DataFrame | Series.check.assert_same_nrows()- Check that this DataFrame/Series has same number of rows as another DataFrame/Series, for example to validate 1:1 joins - DataFrame | Series.check.assert_unique()- DataFrame | Series
Visualize data
.check.hist()- A histogram - DataFrame | Series.check.plot()- An arbitrary plot you can customize - DataFrame | Series
Customizing a check
You can use Pandas Checks methods like the regular Pandas methods. They accept the same arguments. For example, you can pass:
* .check.head(7)
* .check.value_counts(column="species", dropna=False, normalize=True)
* .check.plot(kind="scatter", x="sepal_width", y="sepal_length")
Also, most Pandas Checks methods accept 3 additional arguments:
1. msg: text to display before the result of the check
2. fn: a lambda function that modifies the data displayed by the check
3. subset: limit a check to certain columns
(
iris
.check.value_counts(column='species', msg="Varieties after data cleaning")
.assign(species=lambda df: df["species"].str.upper()) # Do your regular Pandas data processing, like upper-casing the values in one column
.check.head(n=2, fn=lambda df: df["petal_width"]*2) # Modify the data that gets displayed in the check only
.check.describe(subset=['sepal_width', 'sepal_length']) # Only apply the check to certain columns
)
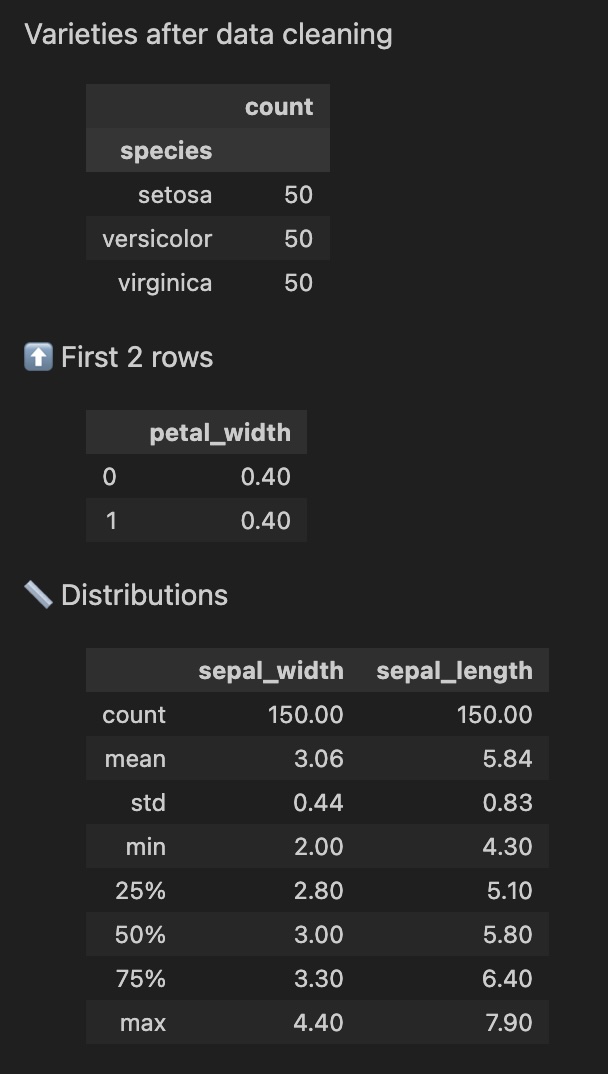
Configuring Pandas Check
Global configuration
You can change how Pandas Checks works everywhere. For example:
import pandas_checks as pdc
# Send Pandas Checks outputs to a log file and disable printing to screen
pdc.set_custom_print_fn(custom_print_fn=logging.info, print_to_stdout=False)
# Set output precision and turn off the cute emojis
# Run `pdc.describe_options()` to see the arguments you can pass to `.set_format()`.
pdc.set_format(precision=3, use_emojis=False)
# Don't run any of the calls to Pandas Checks, globally.
pdc.disable_checks()
💡 Tip:
By default,disable_checks()andenable_checks()do not change whether Pandas Checks will run assertion methods (.check.assert_*).To turn off assertions too, add the argument
enable_asserts=False, such as:disable_checks(enable_asserts=False).
Local configuration
You can also adjust settings within a method chain by bookending the chain, like this:
# Customize format during one method chain
(
iris
.check.set_format(precision=7, use_emojis=False)
... # Any .check methods in here will use the new format
.check.reset_format() # Restore default format
)
# Turn off Pandas Checks during one method chain
(
iris
.check.disable_checks()
... # Any .check methods in here will not be run
.check.enable_checks() # Turn it back on for the next code
)